Web API 项目开发规范
... About 24 min
# Web API 项目开发规范
正所谓:不以规矩,不能成方圆。在使用 Laravel 开发 Web API 之前,我们需要了解 Web API 的相关概念与规范,除此之外,我们还需要去了解业界是如何实现 Web API 的,要把业界案例作为参考,从而制定符合公司技术的 Web API 规范。
# Web API 的设计
# 什么是 Web API
本文中的 Web API 是指「使用 HTTP 协议通过网络调用的 API」,简而言之,Web API 就是一个 Web 系统,通过访问 URI 可以与服务器完成信息交互,或者获得存放在服务器的数据信息等,这样调用者通过程序进行访问后即可机械地使用这些数据。
# 设计优美的 Web API 的重要性
- 设计优美的 Web API 易于使用
- 提升开发效率
- 减少开发周期
- 设计优美的 Web API 便于更改
- 避免更改之后无法使用
- 尽量不影响正在使用的用户
- 设计优美的 Web API 健壮性好
- 安全可靠,难以破解
- 考虑 API 特有安全问题
- 设计优美的 Web API 不怕公之于众
- 不怕受到质疑
- 拥有技术影响
# 如何设计优美的 Web API
- 首先需要决定的是将什么样的信息,通过 API 公开。
- 其次考虑作为访问目标的端点。
- 然后考虑交互方式与合适的响应数据格式。
- 最后还需要考虑安全性以及访问控制等相关内容。
两个重要的设计原则,如下所示:
- 设计规范明确的内容必须遵守相关规范。
- 没有设计规范的内容必须遵守相关事实标准。
# Web API 端点与请求的设计
本文中的端点是指用于访问 API 的 URI。一般而言,因为 API 将各种不同的功能进行了封装,所以会拥有多个不同的端点。
URI:统一资源标志符,一个用于标识某一互联网资源名称的字符串
# Web API 端点基本原则
优秀的 URI 设计,有一个非常重要的原则:容易记忆,URI 包含的功能一目了然。可以把这一条原则细化成多个小原则,如下所示:
- 短小便于输入的 URI
- http://api.example.com/service/api/search
- http://api.example.com/serach √
- 人可以秒懂的 URI
- http://api.example.com/sv/u/
- http://api.example.com/seihin/1
- http://api.example.com/productos/1
- http://api.example.com/products/1 √
- 没有大小写混用的 URI
- http://api.example.com/Users/1
- http://api.example.com/API/getUserName
- http://api.example.com/USERS/1
- http://api.example.com/users/1 √
- 修改方便的 URI
- http://api.example.com/v1/items/alpha/1
- http://api.example.com/v1/items/1 √
- 不会暴露服务器架构的 URI
- http://api.example.com/cgi-bin/get_user.php?user=100
- http://api.example.com/v1/users/100 √
- 规则统一的 URI
- 不统一的 URI
- 获取好友信息:http://api.example.com/friends?id=100
- 发送消息:http://api.example.com/friend/100/message
- 统一的 URI
- 获取好友信息:http://api.example.com/friends/100 √
- 发送消息:http://api.example.com/friends/100/messages √
- 不统一的 URI
# HTTP 方法和 API 端点是什么
HTTP 方法是进行 HTTP 访问时指定的操作,URI 和 HTTP 方法之间的关系可以认为操作对象和操作方法的关系。 如果把 URI 当作 API 的「操作对象 = 资源」,那么 HTTP 方法则表示「进行怎样的操作」。通过用不同的方法访问一个端点,不但可以获取信息,还能修改信息,删除信息。
HTTP 常用方法如下:
- GET:获取信息
- POST:创建信息
- PUT:更新覆盖信息
- PATCH:更新部分信息
- DELETE:删除信息
HTML 文档 Form 元素仅仅支持 GET 和 POST 方法,想要用其他 HTTP 方法,实现方式有两种,都是基于 POST 方法进行实现:
- 通过 _method 参数来实现
- 通过 X-HTTP-Method-Override HTTP Header 实现
# HTTP 方法和 API 端点的设计
目前成型的 API 设计模式如下:
| 功能 | HTTP Method | URI |
|---|---|---|
| 获取用户列表 | GET | http://api.example.com/v1/users |
| 用户注册 | POST | http://api.example.com/v1/users |
| 获取特定用户 | GET | http://api.example.com/v1/users/:id |
| 更新用户信息 | PUT、PATCH | http://api.example.com/v1/users/:id |
| 删除用户信息 | DELETE | http://api.example.com/v1/users/:id |
| 获取当前用户的好友列表 | GET | http://api.example.com/v1/users/:id/friends |
| 添加好友 | POST | http://api.example.com/v1/users/:id/friends |
| 删除好友 | DELETE | http://api.example.com/v1/users/:id/friends/:id |
| 获取指定用户动态 | GET | http://api.example.com/v1/users/:id/updates |
| 获取好友的动态 | GET | http://api.example.com/v1/users/:id/friends/:id/updates |
获取单个数据
规范: GET http://api.example.com/v1/users/:id ,各大公司的实现方式如下所示:
- Twitter:/statuses/retweets/123456.json
- LinkedIn:/companies/123456
- Foursquare:/venues/123456
获取数据集合
规范: GET http://api.example.com/v1/users ,各大公司的实现方式如下所示:
- Twitter:/statuses/mentions_timeline.json
- YouTube:/activities
- LinkedIn:/companies
- Foursquare:/venuegroups/list
- Disqus:/blacklists/list.json
自身信息的别名
规范: me ,各大公司的实现方式如下所示:
- Instagram:/users/self/media/liked
- Etsy:/users/__SELF__/favorites/listings/12345?method=DELETE
- LikedIn:/people/~
- Reddit:/me
- Tumblr:/user/info
- Google Calendar:/users/me/calendarList
- Xing:/users/me
通过这样设计端点,开发时需要输出哪个用户的信息就必须从认证信息中获取,这就必然会导致自身信息的处理和获取其他用户信息的处理要分开进行。可以更容易地防止误将其他用户的个人信息对外公开的 BUG 发生。
# HTTP API 端点设计注意事项
- 使用名词的复数形式
- 复数形式表示资源的集合
- 复数形式与数据库表名一致更加恰当
- 复数形式表示名词等于资源,HTTP 方法表示动词等于操作,这相当于用最简洁的方式描述对资源进行那些操作
- 注意所用的单词
- 所选用的单词要符合 API 的语义性
- 不使用空格及需要编码的字符
- 不够一目了然
- 可能无法访问资源
- 使用连接符来连接多个单词
- 方法
- 蛇形法:http:/api.example.com/v1/users/1/profile_image
- 驼峰法:http:/api.example.com/v1/users/1/profileImage
- 脊柱法:http:/api.example.com/v1/users/1/profile-image
- 点分法:http:/api.example.com/v1/users/1/profile.image
- 事实标准
- Twitter:/statuses/user_timeline
- YouTube:/guideCategories
- Facebook:/me/books.quotes
- LinkedIn:/v1/people-search
- Bit.ly:/v3/user/popular_earned_by_clicks
- Disqus:/api/3.0/applications/listUsage.json
- 推荐使用连字符
-;原因是 Google 推荐使用连字符,使用连字符对 SEO 友好;其次 URI 里的主机名(域名)允许使用连字符而禁止使用下划线,且不区分大小写。而且点子符具有特殊含义。
- 方法
因此,为了使用和主机名一致的规则来统一 URI 命名,用连字符连接多个单词最适合不过。
搜索与查询参数的设计
获取数据量和获取位置的查询参数。这两个参数就是俗称的「分页」参数。各大公司的示例如下:
| 在线服务名称 | 获取数据量 | 获取相对位置 | 获取绝对位置 |
|---|---|---|---|
| count | cursor | max_id | |
| YouTube | maxResults | pageToken | publishedBefore / publishedAfter |
| Flickr | per_page | page | max_upload_date |
| count | start | ||
| - | - | max_id | |
| Last.fm | limit | page | - |
| eBay | paginationInput.entriesPerPage | paginationInput.pageNumber | - |
| del.icio.us | count | results | start |
| bit.ly | limit | offset | - |
| Tumblr | limit | offset since_id | |
| Disqus | limit | offset | - |
| Github | per_page | page | - |
| limit | offset | - | |
| Etsy | limit | offset | - |
从中可以看出一般在线服务会用 limit 、 count 和 per_page 来表示获取的数据量,而使用 page 、 offset 和 cursor 来表示获取数据的位置。
使用相对位置存在的问题
- 在 MySQL 等 RDB 中,当使用
offset或limit来获取指定的数据位置时,随着数据量的增加,响应速度会不断下降。 - 如果数据更新的频率很高,会导致当前获取的数据出现一定的偏差。
用于过滤的参数
在 API 里设置过滤条件,以此来实现搜索用户的功能。各个在线服务实现如下:
- LinkedIn:http://api.linkedin.com/v1/people-search?first-name=Clair
- Tumblr:http://api.tumblr.com/v2/blog/pitchersandpoets.tumblr.com/posts?tag=new+york+yankees
- Instagram:http://api.instagram.com/v1/users/search?q=jack
- Foursquare:http://api.foursquare.com/v2/venues/search?q=apple&categoryId=asad132421&ll=44.3,37.2&radius=800
查询参数和路径的使用区别
在设计 URI 时,必须决定是把客户端指定的特定参数放在查询参数里还是路径里,决策的依据有以下两点:
- 是否是表示唯一资源所需的信息
- 是否可以省略
首先第一点提到了资源是否唯一,这主要基于「URI 表示资源」这一根本思想。像用户 ID 能够表示资源的唯一性,将用户 ID 放在路径中就比较合适。然后是否可以省略,比如罗列、搜索时用到的 offset 、 limit 或 page 参数,如果忽略,很多情况下都会启用默认值而不会出错,所以放在查询参数里更为合适。
# 主机名和端点的共有部分
完整的端点是类似于 https://api.example.com/v1/users 这样的 HTTP 的 URI 信息。 https://api.example.com/v1/ 是 API 的共有部分,对这部分内容的设计也有必要进行一番考量。
| 在线服务 | 端点的共有部分 |
|---|---|
| api.twitter.com/1.1 | |
| Foursquare | api.foursquare.com/v2 |
| Tumblr | api.tumblr.com/v2 |
| Github | api.github.com |
| api.linkedin.com/v1 |
# 通过版本信息来管理 API
- 在 URI 中嵌入版本编号
- 在查询字符串里加入版本信息
- 使用媒体类型来指定版本信息
为了遵循短小便于输入的原则,推荐使用媒体类型来指定版本信息。
# 登录与 OAuth 2.0
OAuth 一般用于面向第三方大范围公开的 API 中的认证工作。
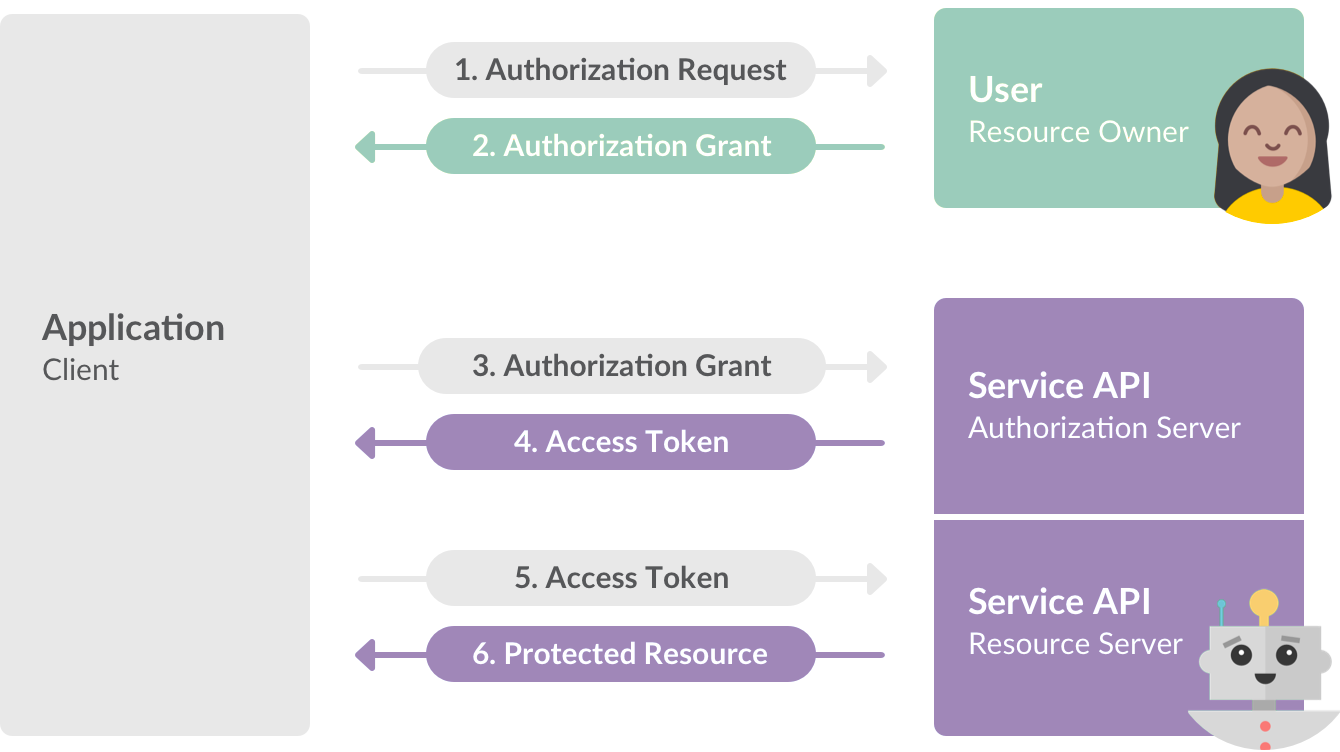
OAuth 2.0 的认证类型(Grant Type)有:
- Authorization Code - 授权码模式
- Client Credentials - 客户端模式
- Implicit - 简化模式
- Resource Owner Password Credentials - 密码模式
根据不同的项目业务需求,可以选择不同的认证类型。
OAuth 的端点示例
- RFC 6749: /token
- Twitter: /oauth2/token
- Dropbox: /oauth2/authorize
- Fackbook: /oauth/access_token
- google: /o/oauth2/token
- github: /login/oauth/access_token
- instagram: /oauth/authorize
- tumblr: /oauth/access_token
当正确的信息送达服务器端后,服务器端便会返回如下 JSON 格式的响应信息
{
"access_token": "令牌",
"token_type": "bearer",
"expires_in": 过期时间,
"refresh_token": "刷新令牌凭证"
}
token_type 的 bearer 是 RFC 6750 定义的 OAuth 2.0 所用的 token 类型。根据 RFC 6750 的定义,
客户端有 3 种方式将 bearer token 信息发送给服务器。
第一种,将 token 信息添加到请求信息的首部时,客户端要用到 Authorization 首部,并按如下方式指定 token 的内容
GET /v1/users HTTP / 1.1
Host: api.example.com
Authorization: Bearer lkj123hjkasd879asdiuoqwe7a
第二种,将 token 信息添加到请求体时,则需要将请求消息里的 Content-Type 设定为 application/x-www-form-urlencoded ,
并用 access_token 来命名消息体里的参数,然后附加上 token 信息
POST /v1/users HTTP / 1.1
Host: api.example.com
Content-type: application/x-www-form-urlencoded
access_token=lkj123hjkasd879asdiuoqwe7a
第三种,以查询参数的形式添加 token 参数时,可以在名为 access_token 的查询参数后指定 token 信息发送给服务器。
GET /v1/users?access_token=lkj123hjkasd879asdiuoqwe7a
Host: server.example.com
# Web API 响应数据的设计
# Web API 响应数据的格式
关于这点不用谈论,选择 JSON 作为默认数据格式即可。
# Web API 响应数据的指定方式
如果客户端需要支持其他的响应数据格式,有三种方法可以向服务端传达这一信息
- 使用查询参数的方法
- https://api.example.com/v1/users?format=xml
- 使用扩展名的方法
- https://api.example.com/v1/users.json
- 使用在请求首部指定媒体类型的方法
- 在
HTTP Header加入Accept: application/json
- 在
推荐使用在请求首部指定媒体类型的方法
# Web API 响应成功的格式
选择合适的状态码来表示响应成功
- 1 字头:消息
- 2 字头:成功
- 3 字头:重定向
| 状态码 | 描述 |
|---|---|
| 200 | 更新/获取资源成功 |
| 201 | 创建资源成功 |
| 204 | 删除资源成功 |
# Web API 响应出错的格式
选择合适的状态码来表示响应出错
- 4 字头:客户端原因引起的错误
- 5 字头:服务端原因引起的错误
| 状态码 | 描述 |
|---|---|
| 400 | 业务错误,具体参见下放业务错误代码 |
| 401 | 认证失败,请返回 认证 检查参数是否有误 |
| 403 | 无权限调用接口,如:未开通 API 功能 |
| 404 | 资源不存在 |
| 405 | 接口请求方式 Method 有误 |
| 422 | 请求参数校验失败 |
| 429 | 触达限流限制 |
| 500 | 服务器应用发生了错误 |
| 502 | 服务器无法连接 |
| 503 | 服务器暂不可用 |
| 504 | 服务器连接超时 |
向客户端返回详细的出错信息
返回出错信息的方法有两种:一种是将详细信息放入 HTTP 响应消息首部,另一种则是通过响应消息体返回。
HTTP 响应消息头
X-MYNAME-ERROR-CODE: 2017
X-MYNAME-ERROR-MESSAGE: Hello world
X-MYNAME-ERROR-INFO: "..."
HTTP 响应消息体
{
"code": 401,
"message": "Bad authentication token",
}
必须使用 HTTP 响应消息体返回
# Web API 响应出错注意事项
发生错误时防止返回
某些 API 在发生错误时会将 HTML 信息写入信息体,但虽说发生了错误,但客户端依然在访问 API,所以仍然期待服务器返回 JSON 或 XML 等数据格式。
维护与状态码
当停止 API 来进行维护工作时,不仅仅要使用 503 状态码来告知用户当前服务已经停止,还要使用 Retry-After 这一 HTTP 首部来告知用户维护结束的时间。
# 禁止使用 HTTP 缓存
HTTP 缓存机制分为两类,过期模型和验证模型。过期模型是指预先决定响应数据的保存期限,当到达期限后就会再次访问服务器来重新获取所需的数据;而验证模型则会轮询当前保存的缓存数据是否为最新数据,并只在服务器端进行数据更新时,才重新获取新的数据。
在 HTTP 协议中,缓存处于可用的状态时成为 fresh 状态,而处于不可用的状态时则成为 stale 状态。过期模型可以通过在服务器的响应消息里包含何时过期的信息来实现。HTTP 1.1 中定义了两种实现方法:一个方法是用 Cache-Control 响应消息首部,
另一个方法是用 Expires 响应消息首部,分别如下所示:
Expires: Fri, 01 Jan 2016 00:00:00 GMT
Cache-Control: max-age=3600
当 Expires 和 Cache-Control 同时使用时, Cache-Control 优先。另外 HTTP 时间格式必须遵循 RFC 1123 的规范,而且只能使用 GMT 作为时区。
验证模型采用了询问服务器的方式来判断当前所保存的缓存是否有效。和到期之前不会发生网络访问的过期模型不同,验证模型会在检查缓存的过程中会不时地去访问网络。
在执行验证模型时,需要应用程序支持附带条件的请求。要进行附带条件的请求,就必须向服务器传达「客户端当前保存的信息的状态」,为此需要用到最后更新日期或 实体标签作为指标。
最后更新时间表示当前数据最后一次更新的日期;而实体标签则是表示某个特定资源版本的标识符。最后更新日期和实体标签会被分别填充在 「Last-Modified」 和 「ETag」 响应信息首部返回给客户端。
HTTP 1.1 还存在「启发式过期」,当服务端没有给出明确的过期时间时,客户端可以决定大约需要将缓存数据保存多久。这时客户端就要根据服务器端的更新频率、 具体状况等信息,自行决定缓存的过期时间。
不希望实施缓存的情况,可以使用「Cache-Control」首部实现,或者在「Expires」使用过去的日期或不正确的日期也能到达到同样的效果。
// 先用验证模型确认返回的资源是否发生了变化,然后根据令牌来确认是否更新缓存
Cache-Control: no-cache
// 直接禁止浏览器以及中间缓存存储任何版本的返回响应。每次请求都要求返回完整的响应
Cache-Control: no-store
# 同源策略和跨域资源共享
通过 ·XHTTPRequest· 对不同的域进行访问将无法获取响应数据,这一原则成为同源策略(Same Origin Policy)。同源策源主要是出于安全方面的考虑,它只允许从相同的源来读取数据,并通过 URI 里的 schema(http,https),Host(api.example.com),端口号的组合来判断是否同源。
- http://www.example.com
- http://api.example.com
- https://www.example.com
- https://www.example.com:8888
上述 URI 皆不同源。
CORS(Cross-Origin Resource Sharing) 跨域资源共享可以解决同源策略带来的问题。实施 CORS 时,客户端需要使用 Origin 请求首部。然后服务端会检查其中的源
是否能够允许被访问。并使用 Allow-Origin 响应首部来返回允许访问的源。
CORS 在特定场景下会先行查询请求是否能被接收。使用 OPTION 方法发送请求。然后服务端会响应这样的请求,并返回如下三个首部:
Access-Control-Allow-Origin: * // 允许源清单
Access-Control-Allow-Methods: * // 允许请求方法清单
Access-Control-Allow-Headers: * // 允许请求头部清单
Access-Control-Allow-Max-Age: 允许事先请求的信息在缓存中保存的时间定义私有的 HTTP 首部,如果将 HTTP 首部作为存放元信息的场所,当需要发送无法找到合适首部的元数据时,可以自定义私有的 HTTP 首部,如下所示:
X-AppName-PixelRatio: 2.0
# Web API 安全的设计
由于 HTTP 协议数据传输采用明文的特点,导致整个传输过程完全透明,任何人都能够在链路中截获、修改或者伪造请求/响应报文。针对 HTTP 明文的特点,常见的攻击手段如下:
# 数据嗅探(Packet Sniffing)
当前越来越多的公共场所开始提供 WiFi 服务,例如星巴克、图书馆、餐厅,然而在这些地方,攻击者却能非常方便地窃取连接同一 WiFi 的用户的通信数据。这一攻击行为叫做数据嗅探。只需将自己的电子设备接入当前 WiFi,并打开数据嗅探工具(WireShark 之类),就能窃取他人的 HTTP 通信数据。如果在公共场所输入私密数据,例如某些网站的账号和密码,无疑将这些信息暴露在攻击者面前。
解决方案:使用 HTTPS 对 HTTP 通信实施加密。HTTPS 能对 URI 路径、查询字符串、协议部分等几乎所有的数据完成加密,防止监听窃取。
# 会话劫持(Session Jacking)
会话劫持是可以基于数据嗅探的基础上进行的,攻击者既然能够截获 HTTP 请求,自然能够拿到对应 HTTP 请求的 Cookie 或 Token,通过伪造 HTTP 请求数据和携带对应 Cookie 或 Token,就能冒充用户去访问对应的接口。
解决方案:使用 HTTPS 对 HTTP 通信实施加密。HTTPS 能对 URI 路径、查询字符串、协议部分等几乎所有的数据完成加密,防止监听窃取。
# 中间人攻击(MITM)
中间人(MITM)攻击是一种攻击类型,其中攻击者将它自己放到两方之间,通常是客户端和服务端通信线路的中间。这可以通过破坏原始频道之后拦截一方的消息并将它们转发(有时会有改变)给另一方来实现。由于 HTTP 不加密、不认证的特点,针对 Web API 的中间人攻击还是比较容易实施的。
解决方案:使用 HTTPS 对 HTTP 通信实施加密的同时,需要客户端需要做好 SSL 证书的验证工作,避免信任了伪造的证书,导致中间人可以解密 HTTPS 的通信数据。
# 跨站脚本攻击(XSS)
XSS 接收用户的输入内容并将其嵌入页面的 HTML 代码,当页面在浏览器里显示时,会自动执行用户输入的 JavaScript 等脚本。一旦页面执行了用户输入的 JavaScript 脚本,攻击者就能访问会话,Cookie 等浏览器里保存的信息,或者篡改页面,甚至还可以不受同源策略的限制进行跨域访问,从而完成任意操作。
解决方案
- 响应头加上
Content-Type: application/json,避免浏览器将响应数据当做text/html来解释渲染。 - 响应头加上
X-Content-Type-Options: nosniff,避免旧版本 IE 浏览器无视Content-Type: application/json的声明而将 JSON 当作 HTML 解释渲染。 - 响应头加上
X-XSS-Protection: 1; mode=block,打开浏览器自带的检测、防御 XSS 的功能,能够防范大部分 XSS 的攻击模式。 - 对相应的 JSON 数据进行转义
# 跨站请求伪造(XSRF)
跨站请求攻击,简单地说,是攻击者通过一些技术手段欺骗用户的浏览器去访问一个自己曾经认证过的网站并运行一些操作(如发邮件,发消息,甚至财产操作如转账和购买商品)。由于浏览器曾经认证过,所以被访问的网站会认为是真正的用户操作而去运行。这利用了 Web 中用户身份验证的一个漏洞:简单的身份验证只能保证请求发自某个用户的浏览器,却不能保证请求本身是用户自愿发出的。
解决方案:使用一次性令牌,需要服务端预先准备好令牌的下发机制。一般利用
X-XSS-Token请求头或 Cookie 携带相关信息去访问接口。
# 拒绝服务攻击(Dos)
拒绝服务攻击即攻击者想办法让目标机器停止提供服务或资源访问。这些资源包括磁盘空间、内存、进程甚至网络带宽,从而阻止正常用户的访问。其实对网络带宽进行的消耗性攻击只是拒绝服务攻击的一小部分,只要能够对目标造成麻烦,使某些服务被暂停甚至主机死机,都属于拒绝服务攻击。拒绝服务攻击问题也一直得不到合理的解决,究其原因是因为这是由于网络协议本身的安全缺陷造成的,从而拒绝服务攻击也成为了攻击者的终极手法。
# 限制每个用户的访问
- 用什么样的机制来识别用户
- 如何确定限速的数值
- 以什么单位来设置限速的数值
- 在什么时候重置限速的数值
- 应对超出上限值的情况
# 向用户告知限速的信息
- X-RateLimit-Limit: 单位时间的访问上限
- X-RateLimit-Reset: 访问次数重置的时间
- X-RateLimit-Remaining: 剩余的访问次数
# 其他安全相关的 HTTP 首部
# X-Frame-Options
通过设置该首部,就可以控制某个指定的页面是否允许在 FRAME、IFRAME 里读取数据。因为存在点击劫持(Click Jacking)的攻击,即攻击者将透明的 IFRAME 元素悄悄加载到其他页面,让用户进行点击操作。虽然 Web API 一般不会有 FRAME 元素的存在,但是加上也不会有什么坏处
X-Frame-Options: deny
# Content-Security-Policy
该首部用于 IMG 元素、SCRIPT 元素、LINK 元素等指向的目标资源的范围,一般来说 Web API 不需要读取其他静态资源,所以可以通过这个首部告诉浏览器不去读取静态资源。
Content-Security-Policy: default-src 'none'
# Strict-Transport-Security
该首部用于实现 HSTS 功能,能够限制浏览器只使用 HTTPS 方式来访问某个 Web 服务。
Strict-Transport-Security: max-age=15768000
# Public-Key-Pins
该首部用于实现 HPKP 功能,用于检查站点的 SSL 证书是否是伪造的。服务端会在该首部内写入证书内容的散列值和有效期,当浏览器访问时,就会通过该散列值来验证网站持有的证书是否合法。
Public-Key-Pins: max-age=XXX; pin-sha256=XXXX; pin-sha256=XXX;
# Set-Cookie
在 Set-Cookie 首部设置名为 Secure 和 HttpOnly 的属性,可以大大加强安全性。Secure 表示只有在 HTTPS 通信时才能被发送给服务端。HttpOnly 表示 Cookie 信息仅用于 HTTP 通信,浏览器不能使用 JavaScript 脚本来访问。
Set-Cookie: session=XXXX; Path=/; Secure; HttpOnly
# Web API 开发确认清单
Web API 检查清单,基于【Web API的设计与开发】书籍内容进行丰富,并给予了必要的解释与说明,方便大家快速浏览与统一协作。
# 确认清单
- [ ] 短小便于输入的 URI
- http://api.example.com/service/api/search
- http://api.example.com/serach √
- [ ] 人可以秒懂的 URI
- http://api.example.com/sv/u/
- http://api.example.com/seihin/1
- http://api.example.com/productos/1
- http://api.example.com/products/1 √
- [ ] 没有大小写混用的 URI
- http://api.example.com/Users/1
- http://api.example.com/API/getUserName
- http://api.example.com/USERS/1
- http://api.example.com/users/1 √
- [ ] 修改方便的 URI
- http://api.example.com/v1/items/alpha/1
- http://api.example.com/v1/items/1 √
- [ ] 不会暴露服务器架构的 URI
- http://api.example.com/cgi-bin/get_user.php?user=100
- http://api.example.com/v1/users/100 √
- [ ] 规则统一的 URI
- 不统一的 URI
- 获取好友信息:GET http://api.example.com/friends?id=100
- 发送站内消息:POST http://api.example.com/friend/100/message
- 统一的 URI
- 获取好友信息:GET http://api.example.com/friends/100 √
- 发送站内消息:POST http://api.example.com/friends/100/messages √
- 不统一的 URI
- [ ] URI 单词要求符合正确的语义性,例如:
- 照片应该是 photo 而不是 picture
- [ ] URI 里用到的名词是否采用了复数形式
- 因为URI表示资源的集合,所以作者是建议总是使用复数形式。
- [ ] URI 不能存在空格符和需要编码的字符
- URL是会被urlencode编码的,所以不要在URI里使用空格(会被编码成+)、UTF-8字符、乱七八糟的符号等。
- 不能影响可读性
- [ ] URI 单词和单词之间必须使用 - 连字符链接多个单词,例如:
- productSku、ProductSpu、vip_user
- product-sku、product-spu、vip-user √
- [ ] 必须使用 HTTPS 协议
- [ ] 建议使用合适的 HTTP 方法
- [ ] 无需缓存的数据,需要添加 Cache-Control: no-cache 首部信息
- [ ] 需要缓存的数据,合理使用 Cache-Control、ETag、Last-Modified、Vary 等缓存策略
- [ ] 合理配置 CORS
- [ ] 响应数据格式采用 JSON 作为默认格式
- [ ] 响应数据认真执行 JSON 转义
- [ ] 响应数据出错时,不能返回 HTML 数据(生产环境)
- [ ] 响应数据里面需要添加各种安全性的首部,例如:
- Secure:表示 Cookie 只能在访问 https 链接时才能被发送给服务端,这样可以彻底避免 Cookie 被攻击者在网络中嗅探到。
- HttpOnly:Cookie 仅能供 HTTP 调用时使用,而不允许 JavaScript 直接获取 Cookie,这样可以避免网站出现 XSS 漏洞的时候,攻击者通过 JS 代码把用户的会话 Cookie 盗走。
- [ ] 通过版本信息来管理 API(三选一)
- 在 URI 中嵌入版本编号
- 在查询字符串里加入版本信息
- 使用媒体类型来指定版本信息(推荐)
- [ ] API 版本命名方式需要遵循语义化版本控制规范
- 如果软件API没有变更,只是修复服务端BUG,那么就增加补丁版本号
- 对软件API实施了向下兼容的变更,增加次版本号
- 对软件API实施了不向下兼容的变更时,增加主版本号
- [ ] API 在接收参数时需要仔细检查非法参数
- 前端后端同时校验
- [ ] API 更新数据操作必须做到幂等性
- 举例,支付请求重复发送时,不会要求用户支付多次,退款请求重复发送时,不会重复退款。
- [ ] API 需要根据业务实现访问限速
- 获取验证码请求和产品列表请求,最高每分钟请求频率肯定不一致。
# 待商榷的
- 是否使用 RESTFul 风格
- 增加了心智负担,需要一定的接口设计能力
- 采用传统风格(控制器 + 方法名)的方式可能不用耗时在 URL 命名上,例如:获取用户列表、获取单一用户、当前用户
- RESTful
- GET http://api.example.com/users?page=1
- GET http://api.example.com/users/1
- GET http://api.example.com/users/me
- 传统风格
- GET http://api.example.com/user/get-user-list?page=1
- GET http://api.example.com/user/get-user?id=1
- GET http://api.example.com/user/get-current-user
- RESTful
- 是否使用复数形式来表现 URI
- 使用 RESTFul 必然就是使用复兴形式表现 URI
- 由于控制器、模型的命名通常都是单数形式,使用传统风格用单数在风格上会更加统一